Introduction
Interethnic differences in drug-metabolizing enzyme
activity have been associated with inter-individual differences in
the efficacy and toxicity of many medications (1). Among drug-metabolizing enzymes, the
cytochrome P450 (CYP), a supergene family involved in the
phase I reactions of the metabolism of several drugs and endogenous
compounds, has increasingly been recognized to have clinically
significant consequences (2).
Cytochrome P450 1A2 (CYP1A2), one of the CYP enzyme
isoforms, is of particular interest because it exhibits a genetic
polymorphism.
CYP1A2, mapped to the positive strand of the
long arm of chromosome 15 at 15q24.1, is predominantly expressed in
the human liver and at lower levels in intestine, pancreas, lung
and brain (3). The human
CYP1A2 enzyme has been demonstrated to be responsible for
many commonly used drugs, including caffeine, imipramine,
paracetamol, clozapine, theophylline, tacrine, phenacetin and some
neurotoxins (4). In addition,
CYP1A2 is known to gain further importance in the metabolic
activation of numerous carcinogens (5). Therefore, any alteration to
CYP1A2 activity has been suggested to be a susceptibility
factor for drug metabolism and the etiology of developing cancers
and other diseases (6).
Like other drug metabolizing enzymes, numerous
factors have been presented to elucidate the mechanisms underlying
the inter-individual differences in CYP1A2 activity, such as
race, gender, environmental exposure to inducers or inhibitors and
genetic factors (7). With respect
to genetic factors, several alleles and additional haplotype
variants have been identified in coding and non-coding regions of
the CYP1A2 gene, in particular in the CYP1A2 upstream
sequence and the intron 1 region (CYP allele nomenclature
website at http://www.cypalleles.ki.se/). The frequencies of
these polymorphisms display interethnic variability particularly
between those of European and East Asian ancestry (8).
Tibet, as a part of China, contains a large number
of high altitude populations that have a distinctive suite of
physiological traits that enable them to tolerate environmental
hypoxia. Because few data are available on the investigation of the
CYP1A2 genotype in the Tibetan population, the aim of the
present study was to determine the CYP1A2 genotype profile
of a random Tibet population by screening for the main allelic
variants and compare to the allelic frequencies of those previously
reported from other ethnic groups. It is hoped that the results
will prospectively offer a preliminary basis for more rational
usage of drugs that are substrates for CYP1A2.
Materials and methods
Subjects and DNA extraction
A total of 96 unrelated Chinese healthy volunteers
(48 males and 48 females) of Tibetan origin, mostly students or
employees at Xizang Minzu University (Xi'an, China), were enrolled
in the study. All of the individuals lived in the same region at
the time of the study and were of Tibetan ancestry without any
known ancestry from other ethnicities. The study protocol was
approved by The Human Research Committee of Xizang Minzu University
(Xi'an, China), and each volunteer gave written informed consent to
participate in the study. Peripheral blood samples were collected
and stored after centrifugation at −70°C until analysis, and
genomic DNA was isolated and purified using a commercial blood
Genomic DNA extraction kit (Xi'an GoldMag Nanobiotech Co., Ltd.,
Xi'an, China) according to the manufacturer's recommendations.
Polymerase chain reaction (PCR) and
DNA sequencing
The primer pairs designed to amplify the 5′ flanking
regions, all exons and all introns of the CYP1A2 gene are
listed in Table I. The PCR was
conducted in a total volume of 10 µl consisting of 1 µl genomic DNA
(20 ng/µl), 0.5 µl each primer pair (5 µM), 5 µl HotStart
TaqMasterMix (Qiagen China Co., Ltd., Shanghai, China), and 3 µl
deionized water. PCR amplification consisted of an initial
denaturation step at 95°C for 15 min followed by 35 cycles of
denaturation at 95°C for 30 sec, annealing at 55–64°C for 30 sec,
extension at 72°C for 1 min. The final extension step was performed
at 72°C for 3 min. The PCR products were purified and sequenced on
an ABI Prism 3100 sequencer (Applied Biosystems; Thermo Fisher
Scientific, Inc., Waltham, MA, USA) using a BigDye Terminator Cycle
Sequencing kit (version, 3.1; Applied Biosystems; Thermo Fisher
Scientific, Inc.).
 | Table I.Primers used for human CYP1A2 gene
amplification. |
Table I.
Primers used for human CYP1A2 gene
amplification.
| Region | Primer sequence
(5′-3′) | Fragment size
(bp) |
|---|
| CYP1A2_1_F |
AATCGATATGGCAATCAAATGCAAA |
|
| CYP1A2_1_R |
CCCGTCTTTCTGTCCCCACT | 740 |
| CYP1A2_2_F |
TAGGCTCCCTACCCTGAACC |
|
| CYP1A2_2_R |
AACATGAACGCTGGCTCTCT | 919 |
| CYP1A2_3_F |
GTCACTGGGTAGGGGGAACT |
|
| CYP1A2_3_R |
AAGGTGTTGAGGGCATTCTG | 896 |
| CYP1A2_4_F |
CTGGCACTGTCAAGGATGAG |
|
| CYP1A2_4_R |
ATTGCAGGACTCTGCTAGGG | 909 |
| CYP1A2_5_F |
CAGGACTTTGACAAGGTGAGC |
|
| CYP1A2_5_R |
CATAGCCCAGGCTCAAACC | 912 |
| CYP1A2_6_F |
CCTGTTCAAGCACAGCAAGA |
|
| CYP1A2_6_R |
AACACAGAGGACAAGCAGAGC | 903 |
| CYP1A2_7_F |
CCTGTTATGTGCCTGCTGTG |
|
| CYP1A2_7_R |
GGGGATTCAGGCCTCTTACT | 899 |
| CYP1A2_8_F |
TCCCAGTGCCCTCTGTGCCA |
|
| CYP1A2_8_R |
GCCTTCCTGACTGCTGAACCTGC | 848 |
| CYP1A2_9_F |
AACAGCCAAGTGCGCAGCCA |
|
| CYP1A2_9_R |
TCGCCTGAGGTACCCCACCT | 881 |
| CYP1A2_10_F |
AGGTGGGGTACCTCAGGCGA |
|
| CYP1A2_10_R |
GAGGTGCCTGGGGGAGGGAG | 930 |
| CYP1A2_11_F |
TTTGGTTCCTTCCCACCTACCCTT |
|
| CYP1A2_11_R |
GAAGAGAAACAAGGGCTGAGTCCCC | 511 |
| CYP1A2_12_F |
TGCTGTTTGGCATGGGCAAG |
|
| CYP1A2_12_R |
TCTGGTGATGGTTGCACAATTC | 926 |
| CYP1A2_13_F |
AGAATTGTGCAACCATCACCAGAA |
|
| CYP1A2_13_R |
CCAGTCTCAGGACTCAAGCACCA | 921 |
Statistical analysis
The sequences were edited and assembled using
Sequencher software (version, 4.10.1; Gene Codes Corporation, Ann
Arbor, MI, USA). Allele nomenclature was assigned according to the
Human Cytochrome P450 (CYP) Allele Nomenclature Committee
(http://www.cypalleles.ki.se/).
Differences in allele frequencies between Tibet and other ethnic
populations were measured by Fisher exact test. P<0.05 was
considered to indicate a statistically significant difference. The
observed genotype frequencies of CYP1A2 were also estimated
by the Hardy Weinberg law for the predicted frequencies. The
linkage equilibrium (LD) coefficient (D') between each genetic
variant was analyzed by Haploview software (version, 4.1; Daley Lab
at the Broad Institute, Cambridge, MA, USA).
Protein prediction of novel
mutations
PolyPhen-2 (http://genetics.bwh.harvard.edu/pph/) and SIFT
(http://blocks.fhcrc.org/sift/SIFT.html) software were
performed to predict the effect of missense variants on the protein
function. Based on the SIFT score, SIFT scores ≤0.05 were predicted
by the algorithm to be evolutionary conservation and intolerance to
substitution, whereas scores >0.05 were considered tolerant (not
likely to affect protein function) (9). The PolyPhen-2 score ranges from 0 to
1, and PolyPhen-2 scores >0.85, between 0.85 and 0.15, and
<0.15 were coded as ‘probably damaging’, ‘possibly damaging’ and
‘benign’, respectively (10).
Results
Single nucleotide polymorphism (SNP)
discovery
In the current study, the authors used direct
sequencing to analyze sequence variation within the CYP1A2
gene among 96 healthy Tibetans. The analyses covered the proximal
promoter region, all exons as well as surrounding intronic regions
and variable lengths of the flanking regions. Table II presented all the CYP1A2
mutation variations in this population. The most frequent
polymorphism was the C-163A change in intron 1 which had 88.54%
frequency, followed by G2321C change in intron 4 which had 37.5%
frequency and T-739G change in intron 1 which had 20.83% frequency
in the healthy group. Both 2159G>A and 5347C>T had similar
results (13.5%), correspondingly. Additionally, among a total of 14
nucleotide variants detected, the authors detected three novel
CYP1A2 variants (795G>C, 1690G>A and 2896C>T) in
exon 2 and intron 5 region with minor allele frequency of 1.04%, of
which one variant (795G>C) resulted in an amino acid change from
glutamine to histidine at position 265.
| Table II.CYP1A2 polymorphisms and their
frequencies in a Chinese Tibetan population. |
Table II.
CYP1A2 polymorphisms and their
frequencies in a Chinese Tibetan population.
| Polymorphism | Location | Flanking
sequence | Minor allele | CYP
nomenclature | Reference
dbSNP | Amino acid
translation | Predicted effect on
protein structure/function using PolyPhen | Frequency (%) |
|---|
| −739T>G | Intron 1 | GGTGTAGGGG K
CCTGAGTTCC | G |
CYP1A2*1E/*1G/*1J | rs2069526 | / |
| 20.83 |
| −163C>A | Intron 1 | CTCTGTGGGC M
CAGGACGCAT | A |
CYP1A2*1F/*1J/*1K | rs762551 | / |
| 88.54 |
| 223G>A | Exon 2 | CTACGGGGAC R
TCCTGCAGAT | A |
| rs150164960 | Val75Ile | Benign | 1.04 |
| 795G>C | Exon 2 | GGTTCCTGCA S
AAAACAGTCC | C | Novel | Novel | Gln265His | Benign | 1.04 |
| 1202C>T | Intron 2 | TTCACACTAA Y
CTTTTCCTTC | T |
| rs4646425 | / |
| 9.38 |
| 1514G>A | Exon 3 | TAGAGCCAGC R
GCAACCTCAT | A | CYP1A2*13 | rs35796837 | Gly299Ser | Benign | 3.13 |
| 1690G>A | Intron 3 | ACAACATACT R
AGATCTGGCT | A | Novel | Novel | / |
| 1.04 |
| 2159G>A | Intron 4 | GAAGCCTTGA R
ACCCAGGTTG | A |
CYP1A2*1M/*1Q/*17 | rs2472304 | / |
| 13.54 |
| 2321G>C | Intron 4 | TGGGGTATAA S
AGGGGATAAT | C |
| rs3743484 | / |
| 37.50 |
| 2410G>A | Exon 5 | AGGGAGCGGC R
GCCCCGGCTC | A |
| rs55918015 | Arg356Gln | Benign | 4.17 |
| 2896C>T | Intron 5 | AATGCCGACA Y
GAGCTTCCTC | T | Novel | Novel | / |
| 1.04 |
| 3613T>C | Intron 6 | GAACTGTTTA Y
ATAATGAAAG | C |
| rs4646427 | / |
| 9.38 |
| 5112C>T | Exon 7 | GCCGATGGCA Y
TGCCATTAAC | T | CYP1A2*14 | rs45486893 | Thr438Ile | Possibly
damaging | 9.38 |
| 5347C>T | Exon 7 | TCTCCATCAA Y
TGAAGAAGAC | T |
CYP1A2*1B/*1G/*1H | rs2470890 | Asn516= |
| 13.54 |
Allele & genotype frequencies
A total of eight different CYP1A2 alleles and
genotypes were determined based on the polymorphisms identified in
the current study (Table III).
Hardy-Weinberg equilibriums were assessed and all CYP1A2
allele and genotype frequencies were in accordance with the
Hardy-Weinberg equilibrium. The wild-type allele, CYP1A2*
1A, with a frequency of 6.77%, was classified as normal
enzyme activity. Besides the wild-type allele, CYP1A2*
1B (58.33%) and CYP1A2*1F (14.58%) were the
best-characterized defect alleles in the Chinese Tibetan
population, of which CYP1A2*1F alleles were
putatively linked to higher inducibility of the enzyme.
CYP1A2*1G, CYP1A2*1J,
CYP1A2*1M, CYP1A2*13 and
CYP1A2*14 alleles have been included in the table, as
these were the most scarce alleles in the study population. They
occurred at a frequency of 1.56–5.21% in the current study
population.
| Table III.Allele and genotype frequencies of
CYP1A2 variants in Chinese Tibetan subjects. |
Table III.
Allele and genotype frequencies of
CYP1A2 variants in Chinese Tibetan subjects.
| Allele | Total (n=192) | Phenotype | Frequency (%) |
|---|
| *1A | 13 | Normal | 6.771 |
| *1B | 112 | / | 58.333 |
| *1F | 28 | Higher
inducibility | 14.583 |
| *1G | 10 | / | 5.208 |
| *1J | 10 | / | 5.208 |
| *1M | 7 | / | 3.646 |
| *13 | 3 | / | 1.563 |
| *14 | 9 | / | 4.688 |
|
| Genotype | Total (n=96) | Phenotype | Frequency (%) |
|
| *1A/*1B | 13 | / | 13.542 |
| *1B/*1B | 16 | Higher
activity | 16.667 |
| *1B/*1F | 28 | / | 29.167 |
| *1B/*1G | 10 | / | 10.417 |
| *1B/*1J | 10 | / | 10.417 |
| *1B/*1M | 7 | / | 7.292 |
| *1B/*13 | 3 | / | 3.125 |
| *1B/*14 | 9 | / | 9.375 |
In relation to genotypes, the most frequent
genotypes were * 1A/* 1B (13.54%), * 1B/*
1B (16.67%) and * 1B/* 1F (29.17%) (Table III). All five other genotypes
presented frequencies of <10.5% in the study. In addition,
individuals with the * 1B/* 1B genotype have been
associated with a higher activity of the enzyme.
Interethnic variability
In order to better understand the occurrence and
distributional patterns of the common mutation allele amongst
different ethnic groups, the data were compared with those from
previous investigations in different countries and ethnic groups in
Caucasians, Africans, Arabs and Asians (Table IV). C-163A (88.54%) was most
frequent among the Tibetan population, when compared with T-739 G
(20.83%) and C5347T (13.54%). The allele frequency of C-163A and
T-739G was significantly higher than that in Caucasians, Africans,
Arabs and Asians, but allelic distributions of C-163A were
relatively equal to that in Malays (78%), and T-739G was relatively
similar to Tunisia (13.5%), Southern Chinese (9.3%) and Indians
(10%). For C5347T, Tibetans demonstrated a relatively lower
frequency of mutation compared with Caucasians (48–64.4%), but was
similar to that in Africans (20.9%) and Asians (12.0–20.4%) with
the only exception of South Asians (35%), which was significantly
higher than Tibetans.
| Table IV.Distribution of mutant allele
frequencies of CYP1A2 −739T>G, −163C>A and 5347C>T in
different ethnicities. |
Table IV.
Distribution of mutant allele
frequencies of CYP1A2 −739T>G, −163C>A and 5347C>T in
different ethnicities.
| Ethnic group | Study population
no. | −163C>A
(*1F/*1J/*1K) | −739T>G
(*1E/*1G/*1J) | 5347C>T
(*1B/*1H/*1G) | Reference |
|---|
| Tibetan | 96 | 88.54 | 20.83 | 13.54 | Present study |
| Caucasian |
|
|
|
|
|
|
British | 65 | 66.2b | 0.77b | ND | PMID: 12534642 |
|
Bulgarian | 138 | 72.0b | ND | ND | PMID: 18021343 |
|
Caucasian | 495 | 68.2b | 1.6b | ND | PMID: 16307269 |
|
Caucasian | 194 | 73.7b | 4.1b | 64.4b | PMID: 18231117 |
|
Caucasian | 236 | 68.0b | ND | ND | PMID: 10233211 |
| Costa
Rican | 932 | 60.0b | ND | ND | PMID: 15466009 |
|
European | 166 | 69.0b | 5.0b | 48.0b | PMID: 22948892 |
|
German | 150 | 68.0b | ND | ND | PMID: 21918647 |
|
Hawaiian | 194 | 71.4b | ND | ND | PMID: 12925300 |
|
Hungarian | 396 | 68.6b | ND | ND | PMID: 25461540 |
|
Italian | 95 | 66.8b | ND | ND | PMID: 16188490 |
|
Roman | 404 | 56.9b | ND | ND | PMID: 25461540 |
|
Serbian | 262–264 | 61.1b | 3.4b | ND | PMID: 20390257 |
|
Swedish | 194 | 71.4b | 2.3b | ND | PMID: 17370067 |
|
Swedish | 1170 | 71.0b | ND | ND | PMID: 12445029 |
|
Spanish | 117 | 2.0b | 2.0b | ND | PMID: 12920202 |
|
Swiss | 100 | 68.0b | ND | ND | PMID: 12851801 |
|
Turkish | 101 | 73.2b | 1.0b | ND | PMID: 20797314 |
|
Turkish | 110 | 73.0b | 1.0b | ND | PMID: 18825963 |
|
Turkish | 146 | 66.8b | 4.8b | 49.7b | PMID: 19450128 |
| African |
|
|
|
|
|
|
Ethiopia | 173 | 60.0b | 10.0a | ND | PMID: 12920202 |
|
Ethiopia | 50–391 | 51.3b | 6.6a | 20.9 | PMID: 20881513 a
genomic biography of the gene behind the human drugmetabolizing
enzyme |
|
Tanzanian | 71 | 49.0b | ND | ND | PMID: 15387446 |
|
Tunisia | 98 | 44.0b | 13.5 | ND | PMID: 19332078 |
|
Tunisia | 27 | 59.3b | ND | ND | PMID: 25921178 |
| South
African | 983 | 61.0b | ND | ND | PMID: 22118051 |
|
Ovambo | 177 | 46.0b | ND | ND | PMID: 16933202 |
|
Zimbabwean | 143 | 57.0b | ND | ND | PMID: 15387446 |
| Arab |
|
|
|
|
|
|
Egyptian | 212 | 68.0b | 3.0b | ND | PMID: 12630986 |
| Saudi
Arabian | 136 | 10.0b | 10.0a | ND | PMID: 12920202 |
|
Jordanian | 550–560 | 67.3b | 6.0b | ND | PMID: 22426036 |
| Asian |
|
|
|
|
|
|
Zhejiang | 43 | 57.0b | ND | ND | PMID: 25117321 |
| Chinese |
|
Chinese | 38–42 | 71.0a | 4.0a | 12.0 | PMID: 20930417 |
|
Chinese | 168 | 67.0b | ND | ND | PMID: 11470995 |
|
Chinese | 79 | 66.0b | ND | ND | PMID: 12445035 |
|
Chinese | 200 | 69.3b | 10.4a | 15.3 | PMID: 18231117 |
|
South | 27 | 70.4a | 9.3 | 20.4 | PMID: 16153396 |
| Chinese |
|
|
Taiwan | 204–208 | 35.0b | 9.7b | 14.0 | PMID: 21121774 |
|
Indians | 41–42 | 58.0b | 10.0 | 12.0 | PMID: 20930417 |
|
Malays | 38–42 | 78.0 | 7.0a | 18.0 | PMID: 20930417 |
|
Mongolian | 153 | 21.2b | ND | ND | PMID: 16933202 |
|
Japanese | 160 | 70.0b | 1.9b | 18.7 | PMID: 18231117 |
|
Japanese | 250 | 62.8b | 3.2b | 19.2 | PMID: 15770072 |
|
Japanese | 159 | 61.3b | 8.2b | ND | PMID: 10551315 |
|
Korean | 150 | 62.7b | 2.7b | ND | PMID: 17370067 |
|
Korean | 1015 | 62.5b | ND | ND | PMID: 19579025 |
|
Korean | 250 | 31.6b | ND | ND | PMID: 16933202 |
|
Korean | 160–186 | 66.1b | 5.4b | 18.3 | PMID: 18231117 |
| South
Asian | 166 | 38.0b | 6.0b | 35.0b | PMID: 22948892 |
LD analysis
To identify relationships between the SNPs
identified in the polymorphism screening, linkage disequilibrium
(LD) analysis was evaluated in Haploview (http://www.broad.mit.edu/mpg/haploview/) using
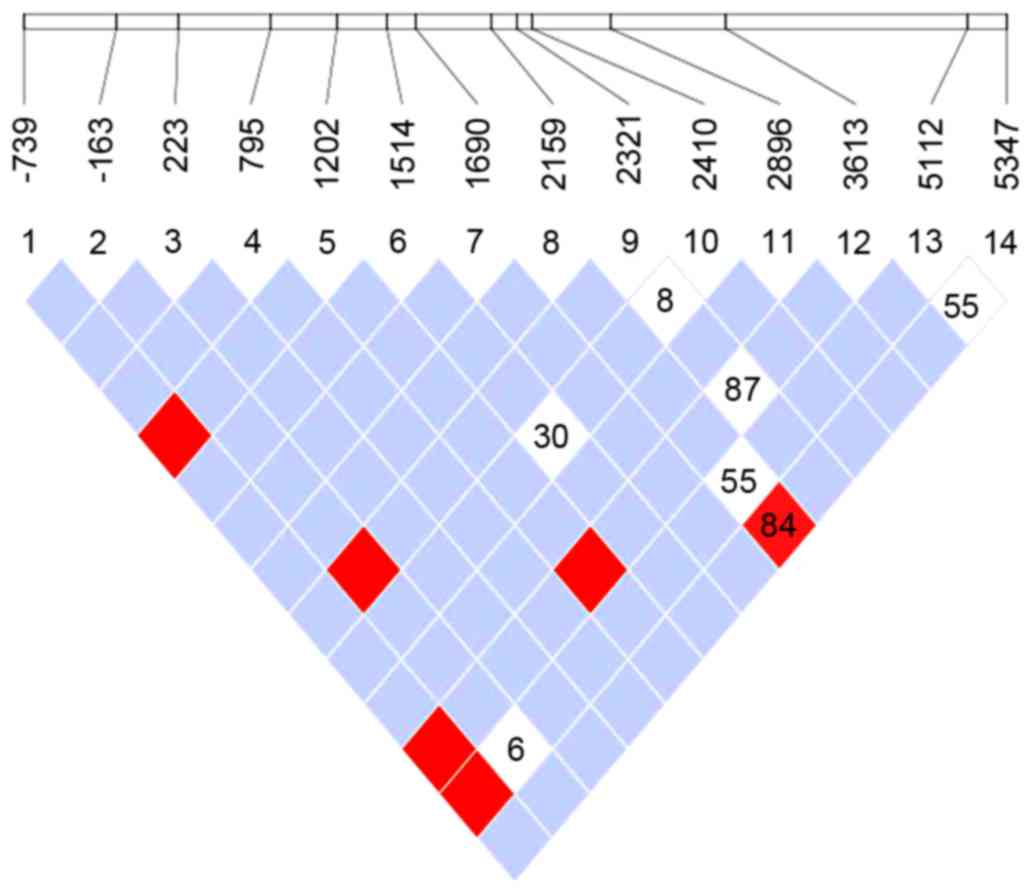
coefficient of linkage disequilibrium D' values (Fig. 1). Even though no distinct LD blocks
or extended haplotypes could be detected in the sequenced data,
some SNPs were identified (−739T>G and 1202C>T, −163C>A
and 2321G>C, 1202C>T and 3613T>C, −739T>G and
3613T>C, −739T>G and 5112C>T) seemed to be linked with
high D'.
Protein function prediction of
non-synonymous mutation
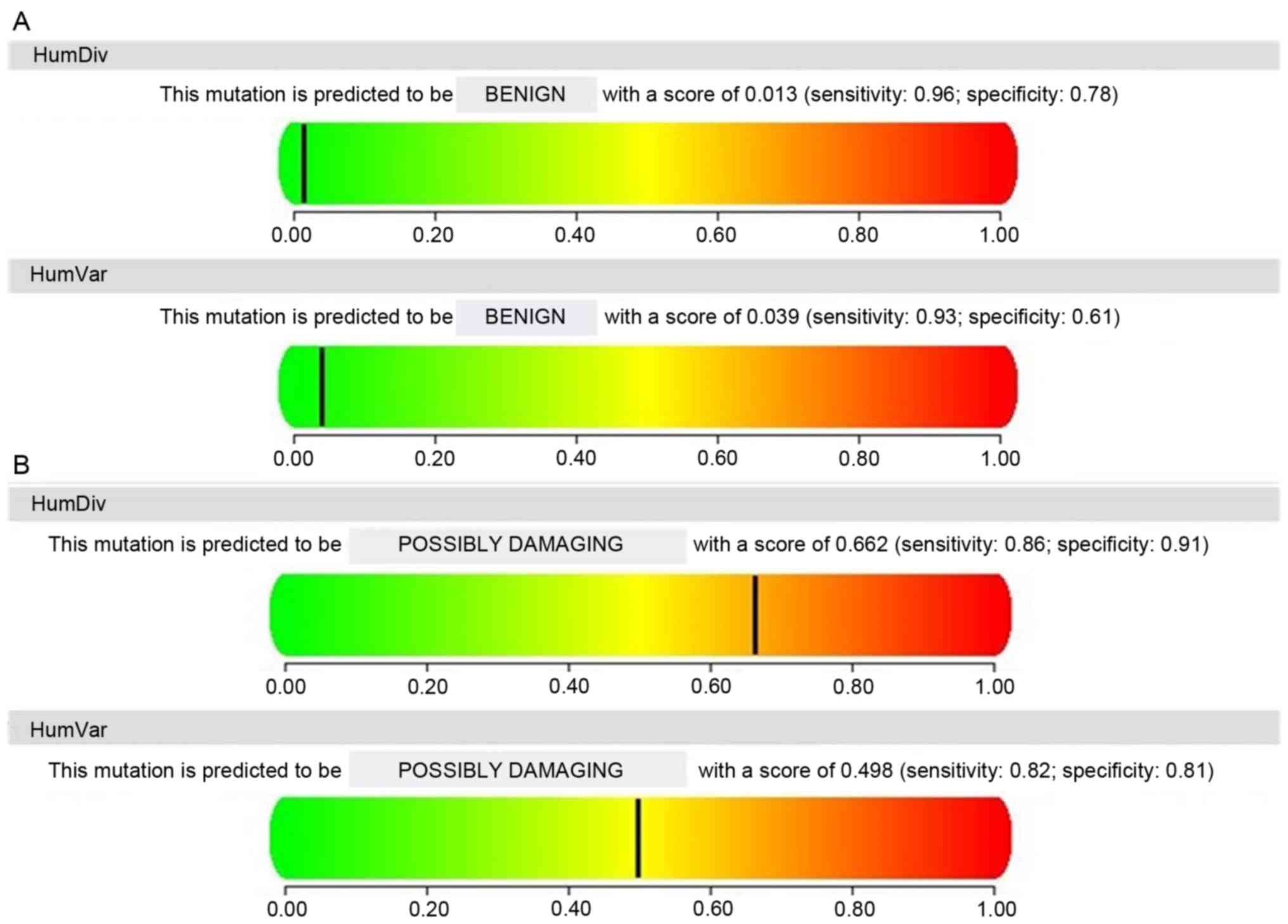
The SIFT scores for the amino acid substitutions
Val75Ile (223G>A), Gln265His (novel variant 795G>C),
Gly299Ser (1514G>A) and Arg356Gln (2410G>A), ranged between
0.07 and 0.72 and were predicted as being tolerated. In contrast,
the Thr438Ile (5112C>T) mutations gave SIFT scores of 0.00,
predicting they were highly likely to affect protein function. To
validate the prediction of SIFT scores, the PolyPhen-2 algorithm
was used to predict variations Val75Ile, Gln265His, Gly299Ser and
Arg356Gln as benign with scores of 0.415, 0.039, 0.045 and 0.002,
respectively, and Thr438Ile as possibly damaging, with a score of
0.281. Four substitutions (Gln265His, Gly299Ser, Arg356Gln and
Thr438Ile) were consistently computationally predicted using both
PolyPhen-2 and SIFT, while Val75Ile was not consistent. The protein
function prediction of variants 5112C>T and 795G>C (novel
variant) is presented Fig. 2
(PolyPhen-2).
Discussion
CYP1A2, one of the major P450 isoforms,
accounts for ~5–20% of the total hepatic CYP content and
contributes to the metabolism of 10% of clinically relevant drugs,
including clozapine and caffeine (3). It has been demonstrated that
CYP1A2 activity has been influenced by the presence of
polymorphic variants, which displays wide interindividual and
interethnic variability. In the present study, the CYP1A2
gene polymorphisms were systematically screened in 96 healthy
Chinese Tibetan subjects. To the best of the authors' knowledge,
these efforts are the first to investigate allelic variants of
CYP1A2 among the Tibetan population to date.
A total of 14 SNPs were detected in the current
study. There were eight SNPs detected in the intron region. The
−163 C>A (* 1F/* 1J/* 1K/* 1M
allele) in intron 1 is the most common CYP1A2 polymorphism
in various population studies (Table
IV). In Tibetans, −163C>A is the most frequently observed
SNP, with an overall frequency of 88.54%, which is significantly
higher than that in Caucasians, Africans, Arabs and Asians (except
Malays). Possible explanations for these differences include:
Genetic background, cultural variants and other factors, such as
living environment, medication use, body composition and dietary
habits (11,12). In addition, much confusion and
controversy still arises as to the available data in literature
about the functional consequences and allele frequencies of
CYP1A2 variants, mainly because of limitation of sample size
and the differing designations of the CYP1A2* 1F
allele (defined as having-163A by The HumanCytochrome P450 Allele
Nomenclature Committee). Sachse et al (4) first reported that smokers homozygous
for the C-allele had, on average, 40% lower CYP1A2 activity
in comparison with those with the A/A genotype. In contrast,
some inconsistent studies have reported that CYP1A2 *
1F mutation was associated with a high inducibility of
CYP1A2 in smokers as well as in nonsmokers (13). It is tempting to speculate the
divergence may be the possibility of the −163C>A occurring in
linkage disequilibrium with another mutation that is responsible
for the increased CYP1A2 inducibility (14). The present study identified a
strong linkage disequilibrium between −163C>A and 2321G>C
polymorphisms (Fig. 1), providing
researchers in the field with abundant clues, however, more studies
are required to shed more light on this idea. Another most
prevalent polymorphism in intron 1 region, −739T>G, was first
reported in in a Japanese population (5). −739T>G is located on the
CYP1A2* 1E, * 1G, * 1J or * 1K
allele, and previous research demonstrated that this polymorphism
has no effect on the enzyme activity (6). −739T>G is the most common variant
among Asians and the frequency of 20.83% found in the present study
is significantly higher than other Asians (Table IV), Caucasians (0.77–5%) (6,8),
Africans (6.6–13.5%) (15,16) and Arabs studied elsewhere (3–10%)
(17,18). Interethnic differences in the
prevalence of −739T>G may be one of the major factors to
consider in large pharmacogenetic studies and clinical applications
in populations of Asian ancestry, such as Chinese Tibetans, since
the proportion of high expressers due to the presence of −739T>G
varies depending on the ethnic background. Among the six SNPs
identified in the exons, the synonymous 5347T>G (* 1B/*
1G/* 1H), was the most common variant among
Caucasians and the frequency of 13.54% identified in the present
study presented a frequency significantly lower than Caucasians,
but it was quite similar to Asians (except South Asians) (Table IV). This may be because these
populations are distributed in different geographical regions,
which may result in the formation of numerous, small, genetically
isolated groups.
In the tested Chinese Tibetan population,
CYP1A2* 1A is referred to as the wild-type allele
with a frequency of 6.77%, which is significantly less when
compared with Swedes (24.4%), Koreans (21.7%), Japanese (34.8%),
Caucasians (33.4%) and Serbs (33.4%) (19–21).
The occurrence of the most prevalent defective alleles,
CYP1A2* 1B (5347T>G), evaluated in Chinese Tibetan
subjects (58.3%) in the present study is slightly lower compared to
the occurrence reported in Caucasians (61.8%), but is higher than
other Chinese population (20.4%) (22). However, the genotype frequencies
observed for * 1B, * 1B in Tibetans (16.67%) was
slightly higher than that in Caucasian (6.19%), Japanese (7.5%),
Korean (10.75%) and other Chinese population (9%). Currently, only
Chen et al (22) reported
that CYP1A2*1B homozygotes demonstrated marginally higher CYP1A2
activity, when compared with CYP1A2* 1A/* 1A
homozygotes (22). Because the *
1B, * 1B genotype is relatively common in Chinese
Tibetan subjects, this genotype may have a major influence in
altered CYP1A2 activity, of course, this requires further
investigation. CYP1A2* 1F resulted from a C>A
substitution at −163 in intron 1 of the promoter region. The
haplotype *1F allele is common with high and comparable frequencies
in various studies. However, the frequencies of CYP1A2*
1F (−163A allele) in Tibetans is 14.58%, which was far less
frequent compared with Caucasians (73.7%) (23), Africans (61%) (24), Arabs (68%) (17) and Asians (69.3%) (23). Since CYP1A2* 1F is
reported to be associated with an effect on enzyme inducibility,
the estimates of their frequencies in the Tibetan population may be
of extreme importance. Compared with the alleles CYP1A2*
1B and CYP1A2* 1F, * 1G, * 1J, *
1M, * 13 and * 14 are relatively rare in
Tibetans, thus the clinical applicability of this pharmacogenetic
testing seems to be limited to a small number of individuals. In
addition, the-163C>A variant is present in the CYP1A2*1F allele,
but it is also presented in several other CYP1A2 haplotypes, two of
which (CYP1A2* 1J and * 1M) were identified in
the sample population. Therefore, it is informative to take the
complete haplotypes into consideration when investigating
associations of phenotype rather than focusing on single SNPs.
After systematically screening the polymorphisms of
the CYP1A2 gene in the healthy population of Chinese Tibetan
subjects, three novel variants were detected that included one
nonsynonymous change at position G795C in exon 2. These variants
are rare but not absent, occurring in <1.04% of the population,
but the current study is the first to report these variants in
Chinese Tibetan subjects. Although the c.795 G>C variation is
predicted to not have an affect on protein function by the SIFT or
PolyPhen algorithms, further functional studies are still necessary
to clarify the role of their clinical significance.
It should be acknowledged that the current research
was designed to investigate the unique distribution of the
CYP1A2 alleles in the Tibetan population. The
characterization of CYP1A2 genetic polymorphisms among
different races may contribute to the outcome and risks to certain
drug therapies.
Acknowledgements
This work was supported by the Key Program of
Natural Science Foundation of Xizang (Tibet) Autonomous Region
(grant no. 20152R-13-11), Major Training Program of Tibet
University for Nationalities (grant no. 13myZP06), Natural Science
Foundation of Xizang (Tibet) Autonomous Region (grant no.
20152R-13-11), and Major Science and Technology Research Projects
of Chinese Ministry of Education (grant no. 211176).
References
|
1
|
Evans WE and Relling MV: Pharmacogenomics:
Translating functional genomics into rational therapeutics.
Science. 286:487–491. 1999. View Article : Google Scholar : PubMed/NCBI
|
|
2
|
Alexov E and Sternberg M: Understanding
molecular effects of naturally occurring genetic differences. J Mol
Biol. 425:3911–3913. 2013. View Article : Google Scholar : PubMed/NCBI
|
|
3
|
Klein K, Winter S, Turpeinen M, Schwab M
and Zanger UM: Pathway-Targeted Pharmacogenomics of CYP1A2 in Human
Liver. Front Pharmacol. 1:1292010. View Article : Google Scholar : PubMed/NCBI
|
|
4
|
Sachse C, Brockmöller J, Bauer S and Roots
I: Functional significance of a C->A polymorphism in intron 1 of
the cytochrome P450 CYP1A2 gene tested with caffeine. Br J Clin
Pharmacol. 47:445–449. 1999. View Article : Google Scholar : PubMed/NCBI
|
|
5
|
Chida M, Yokoi T, Fukui T, Kinoshita M,
Yokota J and Kamataki T: Detection of three genetic polymorphisms
in the 5′-flanking region and intron 1 of human CYP1A2 in the
Japanese population. Jpn J Cancer Res. 90:899–902. 1999. View Article : Google Scholar : PubMed/NCBI
|
|
6
|
Sachse C, Bhambra U, Smith G, Lightfoot
TJ, Barrett JH, Scollay J, Garner RC, Boobis AR, Wolf CR and
Gooderham NJ: Colorectal Cancer Study Group: Polymorphisms in the
cytochrome P450 CYP1A2 gene (CYP1A2) in colorectal cancer patients
and controls: Allele frequencies, linkage disequilibrium and
influence on caffeine metabolism. Br J Clin Pharmacol. 55:68–76.
2003. View Article : Google Scholar : PubMed/NCBI
|
|
7
|
Dobrinas M, Cornuz J, Pedrido L and Eap
CB: Influence of cytochrome P450 oxidoreductase genetic
polymorphisms on CYP1A2 activity and inducibility by smoking.
Pharmacogenet Genomics. 22:143–151. 2012. View Article : Google Scholar : PubMed/NCBI
|
|
8
|
Perera V, Gross AS and McLachlan AJ:
Influence of environmental and genetic factors on CYP1A2 activity
in individuals of South Asian and European ancestry. Clin Pharmacol
Ther. 92:511–519. 2012.PubMed/NCBI
|
|
9
|
Ng PC and Henikoff S: SIFT: Predicting
amino acid changes that affect protein function. Nucleic Acids Res.
31:3812–3814. 2003. View Article : Google Scholar : PubMed/NCBI
|
|
10
|
Liu X, Jian X and Boerwinkle E: dbNSFP: A
lightweight database of human nonsynonymous SNPs and their
functional predictions. Hum Mutat. 32:894–899. 2011. View Article : Google Scholar : PubMed/NCBI
|
|
11
|
Pavanello S, Fedeli U, Mastrangelo G, Rota
F, Overvad K, Raaschou-Nielsen O, Tjønneland A and Vogel U: Role of
CYP1A2 polymorphisms on lung cancer risk in a prospective study.
Cancer Genet. 205:278–284. 2012. View Article : Google Scholar : PubMed/NCBI
|
|
12
|
Chida M, Yokoi T, Fukui T, Kinoshita M,
Yokota J and Kamataki T: Detection of three genetic polymorphisms
in the 5′-flanking region and intron 1 of human CYP1A2 in the
Japanese population. Jpn J Cancer Res. 90:899–902. 1999. View Article : Google Scholar : PubMed/NCBI
|
|
13
|
Han XM, Ou-Yang DS, Lu PX, Jiang CH, Shu
Y, Chen XP, Tan ZR and Zhou HH: Plasma caffeine metabolite ratio
(17X/137X) in vivo associated with G-2964A and C734A polymorphisms
of human CYP1A2. Pharmacogenetics. 11:429–435. 2001. View Article : Google Scholar : PubMed/NCBI
|
|
14
|
Gunes A and Dahl ML: Variation in CYP1A2
activity and its clinical implications: Influence of environmental
factors and genetic polymorphisms. Pharmacogenomics. 9:625–637.
2008. View Article : Google Scholar : PubMed/NCBI
|
|
15
|
Browning SL, Tarekegn A, Bekele E, Bradman
N and Thomas MG: CYP1A2 is more variable than previously thought: A
genomic biography of the gene behind the human drug-metabolizing
enzyme. Pharmacogenet Genomics. 20:647–664. 2010. View Article : Google Scholar : PubMed/NCBI
|
|
16
|
B'Chir F, Pavanello S, Knani J, Boughattas
S, Arnaud MJ and Saguem S: CYP1A2 genetic polymorphisms and
adenocarcinoma lung cancer risk in the Tunisian population. Life
Sci. 84:779–784. 2009. View Article : Google Scholar : PubMed/NCBI
|
|
17
|
Hamdy SI, Hiratsuka M, Narahara K, Endo N,
El-Enany M, Moursi N, Ahmed MS and Mizugaki M: Genotyping of four
genetic polymorphisms in the CYP1A2 gene in the Egyptian
population. Br J Clin Pharmacol. 55:321–324. 2003. View Article : Google Scholar : PubMed/NCBI
|
|
18
|
Aklillu E, Carrillo JA, Makonnen E,
Hellman K, Pitarque M, Bertilsson L and Ingelman-Sundberg M:
Genetic polymorphism of CYP1A2 in Ethiopians affecting induction
and expression: Characterization of novel haplotypes with
single-nucleotide polymorphisms in intron 1. Mol Pharmacol.
64:659–669. 2003. View Article : Google Scholar : PubMed/NCBI
|
|
19
|
Djordjevic N, Ghotbi R, Jankovic S and
Aklillu E: Induction of CYP1A2 by heavy coffee consumption is
associated with the CYP1A2 −163C>A polymorphism. Eur J Clin
Pharmacol. 66:697–703. 2010. View Article : Google Scholar : PubMed/NCBI
|
|
20
|
Ghotbi R, Christensen M, Roh HK,
Ingelman-Sundberg M, Aklillu E and Bertilsson L: Comparisons of
CYP1A2 genetic polymorphisms, enzyme activity and the
genotype-phenotype relationship in Swedes and Koreans. Eur J Clin
Pharmacol. 63:537–546. 2007. View Article : Google Scholar : PubMed/NCBI
|
|
21
|
Soyama A, Saito Y, Hanioka N, Maekawa K,
Komamura K, Kamakura S, Kitakaze M, Tomoike H, Ueno K, Goto Y, et
al: Single nucleotide polymorphisms and haplotypes of CYP1A2 in a
Japanese population. Drug Metab Pharmacokinet. 20:24–33. 2005.
View Article : Google Scholar : PubMed/NCBI
|
|
22
|
Chen X, Wang L, Zhi L, Zhou G, Wang H,
Zhang X, Hao B, Zhu Y, Cheng Z and He F: The G-113A polymorphism in
CYP1A2 affects the caffeine metabolic ratio in a Chinese
population. Clin Pharmacol Ther. 78:249–259. 2005. View Article : Google Scholar : PubMed/NCBI
|
|
23
|
Myrand SP, Sekiguchi K, Man MZ, Lin X,
Tzeng RY, Teng CH, Hee B, Garrett M, Kikkawa H, Lin CY, et al:
Pharmacokinetics/genotype associations for major cytochrome P450
enzymes in native and first- and third-generation Japanese
populations: Comparison with Korean, Chinese, and Caucasian
populations. Clin Pharmacol Ther. 84:347–361. 2008. View Article : Google Scholar : PubMed/NCBI
|
|
24
|
Dandara C, Lombard Z, Du Plooy I, McLellan
T, Norris SA and Ramsay M: Genetic variants in CYP (−1A2, −2C9,
−2C19, −3A4 and −3A5), VKORC1 and ABCB1 genes in a black South
African population: A window into diversity. Pharmacogenomics.
12:1663–1670. 2011. View Article : Google Scholar : PubMed/NCBI
|