Introduction
Myocardial infarction is a result of interrupted
blood flow to a certain area of the heart, which subsequently
damages heart muscle. Among the various symptoms, chest pain or
discomfort that may travel to the shoulder, arm, neck, back or jaw
is the most common (1). Shortness
of breath, feeling faint, nausea and cold sweats may also be
experienced by patients suffering a myocardial infarction.
Myocardial infarction may trigger heart failure, cardiac arrest, an
irregular heartbeat or cardiogenic shock (2), and, as a life-threatening disease
that may lead to severe hemodynamic instability or sudden death, is
one of the major causes of mortality worldwide (3). According to an estimation by the
World Bank, the number of individuals experiencing myocardial
infarction may reach >23 million by 2030 in China (4). Globally, the mortality associated
with acute myocardial infarction has reduced in the past few
decades, however, as a result, the incidence of heart failure has
increased (5). Heart failure
following myocardial infarction is associated with cardiac
remodeling, which leads to ventricular dysfunction and chamber
dilation (6).
Clinically, the occurrence of myocardial infarction
is often unexpected and sudden, which makes it difficult to prevent
and diagnose. Cardiovascular risk factors for heart disease include
circulating blood lipid levels (7), smoking (8), heavy drinking (9), oral contraceptives (10), high intake of anthocyanins
(11), human immunodeficiency
virus infection (12) and a family
history or genetic alterations. A positive family history is among
the strongest cardiovascular risk factors for heart disease,
therefore, numerous studies have aimed to determine the associated
genetic factors of myocardial infarction. For example, Helgadottir
et al (13) reported that
arachidonate 5-lipoxygenase-activating protein variants are
involved in the pathogenesis of myocardial infarction by increasing
the inflammation in the arterial wall and the production of
leukotrienes. In addition, Do et al (14) identified that multiple rare alleles
of the low-density lipoprotein receptor and apolipoprotein A5
confer risk for early-onset myocardial infarction, and a
meta-analysis demonstrated that the rs671 aldehyde dehydrogenase 2
family (mitochondrial) polymorphism increases the risk of
myocardial infarction (15).
Despites the current findings, reliable molecular
prediction in the diagnosis and prevention of myocardial infarction
remains to be discovered. In the present study, using the feature
genes selected from differentially expressed genes (DEGs) in
patients with myocardial infarction compared with controls, a
support vector machine (SVM) classifier and certain risk genes were
screened. These risk genes allow patient samples to be
distinguished from normal controls.
Materials and methods
Microarray data
The GSE34198 microarray dataset (16) was downloaded from the Gene
Expression Omnibus (GEO) database (http://www.ncbi.nlm.nih.gov/geo) and included 49
samples from the peripheral blood of patients with myocardial
infarction and 48 control samples. The platform for GSE34198 was
Illumina human-6 v2.0 expression BeadChip. Affy package RMA in R
version 3.3.1 (17) (http://bioconductor.org/packages/release/bioc/html/affy.html)
was utilized to transfer the array data in GSE34198 into expression
data, which was subsequently normalized by the Z-score method
(18).
DEG identification
The DEGs between patients with myocardial infarction
and control subjects were identified using the Limma version 3.32.8
(http://bioconductor.org/packages/release/bioc/html/limma.html)
(19) with a threshold of
P<0.05 and log|fold change (FC)|>1.
Protein-protein interaction (PPI) network
construction. All screened DEGs were subjected to the human protein
interaction network Human Protein Reference Database (20) (http://www.hprd.org/) for the identification of their
interactions. Subsequently, the interactions were visualized using
Cytoscape 3.4 software (http://www.cytoscape.org/) as the PPI network of DEGs
in myocardial infarction.
Feature gene selection
Usually, significant expression connections exist
between disease feature genes and their connected genes. To
identify the feature genes in myocardial infarction, the
neighborhood score (21) was
employed to identify the feature genes in the PPI network. The
formula for calculating the score was as follows:
Score(i)=12*FC(i)+12*∑n∈N(i)FC(n)N(i)
Where i represents the node in the network, FC
represents the fold change value for the expression level of the
node, N(i) represents the number of the connection nodes to the
selected node and score(i) represents the correlations between the
node(i) and the disease.
By the neighborhood scoring algorithm, the changing
degrees of the nodes under disease will be inferred, along with
their influence on the connecting genes. If the score is >0, the
node and its connected nodes are all highly expressed, and if the
score is <0, the expression of the nodes are low. The nodes
(DEGs) in the PPI network with the top 100 |score| values were
considered to be the feature genes in myocardial infarction.
Tomography cluster analysis
Tomography cluster analysis was conducted to
determine whether the feature genes were differentially expressed
between patient and control samples using Pearson's correlation
coefficient (22) and average
linkage (23). The clustering
results were visualized using heatmaps in R version 3.2.1 (24).
Risk gene identification
To further identify the most significant feature
genes that distinguish patients with myocardial infarction from
controls, the recursive feature elimination (RFE) algorithm was
utilized (25). In this algorithm,
the optional feature gene combinations were selected as the risk
genes in myocardial infarction.
SVM classifier construction
SVM is a supervised classification algorithm that
estimates the attribution of a class by distinguishing and
predicting the samples by the eigenvalues of the features in each
sample (26). A SVM classifier was
performed using the selected risk genes by using 4 samples as the
training dataset and 1 sample as the testing dataset. The receiver
operating characteristic (ROC) curve was drawn to evaluate the
precision and robustness of the SVM classifier. A confusion matrix
in R version 3.2.1 (https://cran.r-project.org/web/packages/ROCR/index.html)
was also employed to visualize the classification results of the
classifier.
Verification of the SVM
classifier
An additional dataset, GSE61144 (27), was downloaded from the GEO
database, which is based on the GPL6106Sentrix Human-6 v2
Expression BeadChip platform. This dataset consists of 7 samples
from patients prior to percutaneous coronary intervention (PCI), 7
from patients following PCI and 10 normal controls. These 24
samples were used to verify the classification effect of the SVM
classifier on myocardial infarction patient samples by R version
3.2.1 e1071 1.6–8 package (https://cran.r-project.org/web/packages/e1071/index.html).
Results
Identification of DEGs
A total of 1,207 DEGs were screened from myocardial
samples compared with normal controls, including 724 downregulated
ones and 483 upregulated ones.
PPI network in myocardial infarction
samples
The PPI network was comprised of 1,083 nodes (genes)
and 46,363 lines (connections). The degrees of the nodes in the
network were calculated, and their distributions are presented in
Fig. 1. The degrees are referring
indexes of the interaction of genes in influencing the development
and process of myocardial infarction. A-kinase-anchoring protein
(AKAP)12 and glycine receptor α (GLRA)2 were two DEGs with a degree
of 1, which means the number of interaction genes is 1 in the PPI
network.
Feature genes and clustering
analysis
The neighborhood scoring method was employed for the
selection of the top 100 feature genes in myocardial infarction
samples. The feature genes with a high neighbor score exhibited
high expression in the patient samples. The top 10 feature genes
are listed in Table I, and
included EH domain-binding protein 1, exocyst complex component 6B,
growth factor receptor-bound protein 10, AKAP12, SRY-box 4, GLRA3,
GLRA2, protein phosphatase 1 regulatory subunit 3A, fatty
acid-binding protein (FABP)4 and mediator complex subunit 13-like.
Clustering analysis was performed on the top 100 feature genes
(Fig. 2), which may allow the
classification of myocardial infarction samples to distinguish them
from the control samples.
 | Table I.Feature genes with top 10 neighbor
scores. |
Table I.
Feature genes with top 10 neighbor
scores.
| Node | NS_score | Log (fold
change) | P-value |
|---|
| EHBP1 | 0.96 | 1.0153 | 0.0004 |
| EXOC6B | 0.96 | 0.9025 | 0.0016 |
| GRB10 | 0.92 | 0.9488 | 0.0009 |
| AKAP12 | 0.91 | 0.9764 | 0.0007 |
| SOX4 | 0.91 | 0.8647 | 0.0026 |
| GLRA3 | 0.91 | −0.8335 | 0.0036 |
| GLRA2 | 0.91 | −0.9855 | 0.0006 |
| PPP1R3A | 0.90 | −1.0402 | 0.0003 |
| FABP4 | 0.90 | 1.0953 | 0.0001 |
| MED13L | 0.90 | 0.7106 | 0.0132 |
Risk genes and SVM classifier
Using the RFE algorithm, a 15-gene combination with
a precision of 85% was obtained (Fig.
3) and these genes were recognized as risk genes in myocardial
infarction. The expression significance of these risk genes is
presented in in Table II, and
these risk genes included hes family bHLH transcription factor 5,
zinc-finger protein 417, GLRA2, olfactory receptor (OR) family 8
subfamily D member 2 (gene/pseudogene), homeobox A7, FABP6,
muscle-associated receptor tyrosine kinase, 5-hydroxytryptamine
receptor 6, glutamate receptor-interacting protein 2, OR family 51
subfamily M member 1, OR family 1 subfamily C member 1, killer cell
lectin-like receptor K1, vascular endothelial growth factor A,
AKAP12 and Ras homolog mTORC1-binding.
| Table II.Risk genes in myocardial infarction
samples. |
Table II.
Risk genes in myocardial infarction
samples.
| Gene | Log (fold
change) | P-value |
|---|
| HES5 | −0.8925 | 0.0018 |
| ZNF417 | −0.8260 | 0.0040 |
| GLRA2 | −0.9855 | 0.0006 |
| OR8D2 | −0.8135 | 0.0045 |
| HOXA7 | 0.7150 | 0.0126 |
| FABP6 | 0.9234 | 0.0013 |
| MUSK | −0.7975 | 0.0054 |
| HTR6 | −0.7651 | 0.0076 |
| GRIP2 | −0.9973 | 0.0005 |
| OR51M1 | −0.8125 | 0.0046 |
| OR1C1 | −0.7755 | 0.0068 |
| KLRK1 | −0.9248 | 0.0013 |
| VEGFA | 0.8442 | 0.0032 |
| AKAP12 | 0.9764 | 0.0007 |
| RHEB | 0.9288 | 0.0012 |
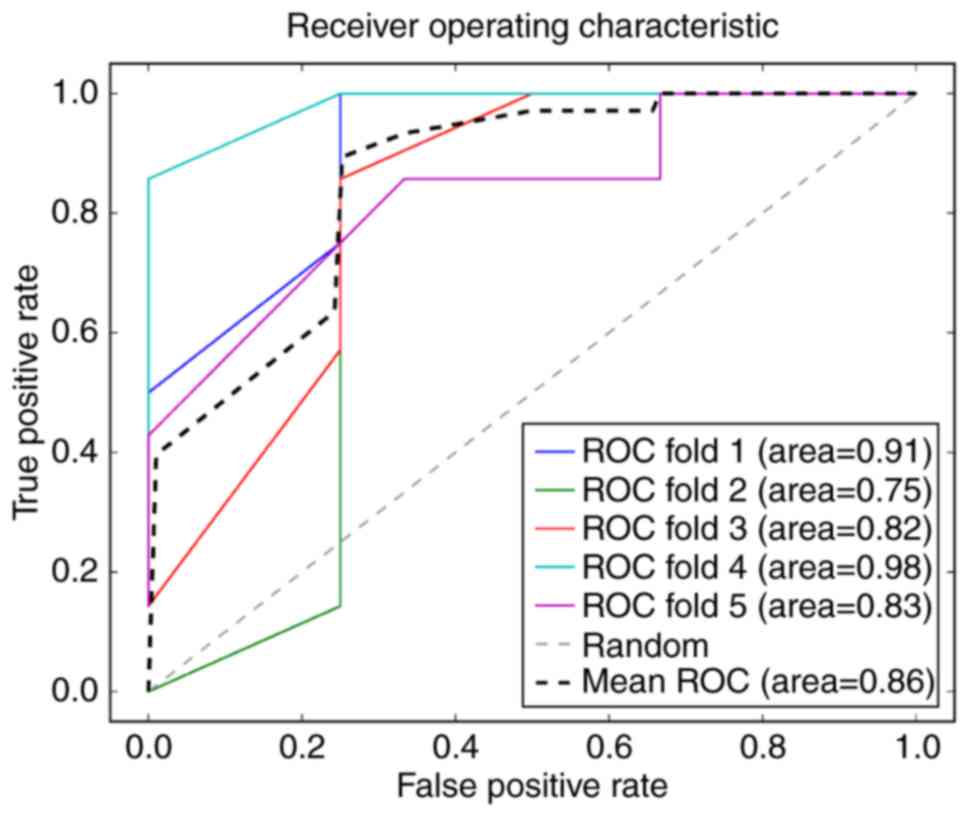
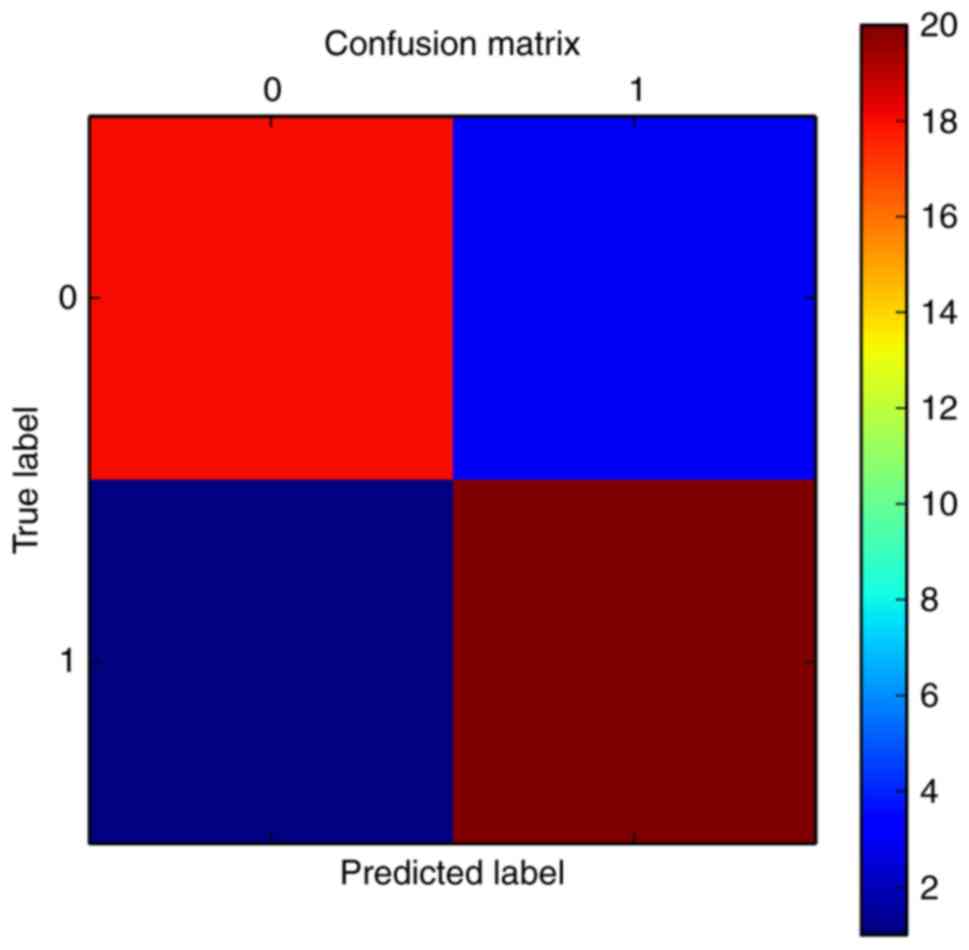
The average precision of the SVM classifier was 86%,
as indicated in the ROC curve (Fig.
4), which was 88% to the patient samples following
visualization by a confusion matrix (Fig. 5). The classification effect was
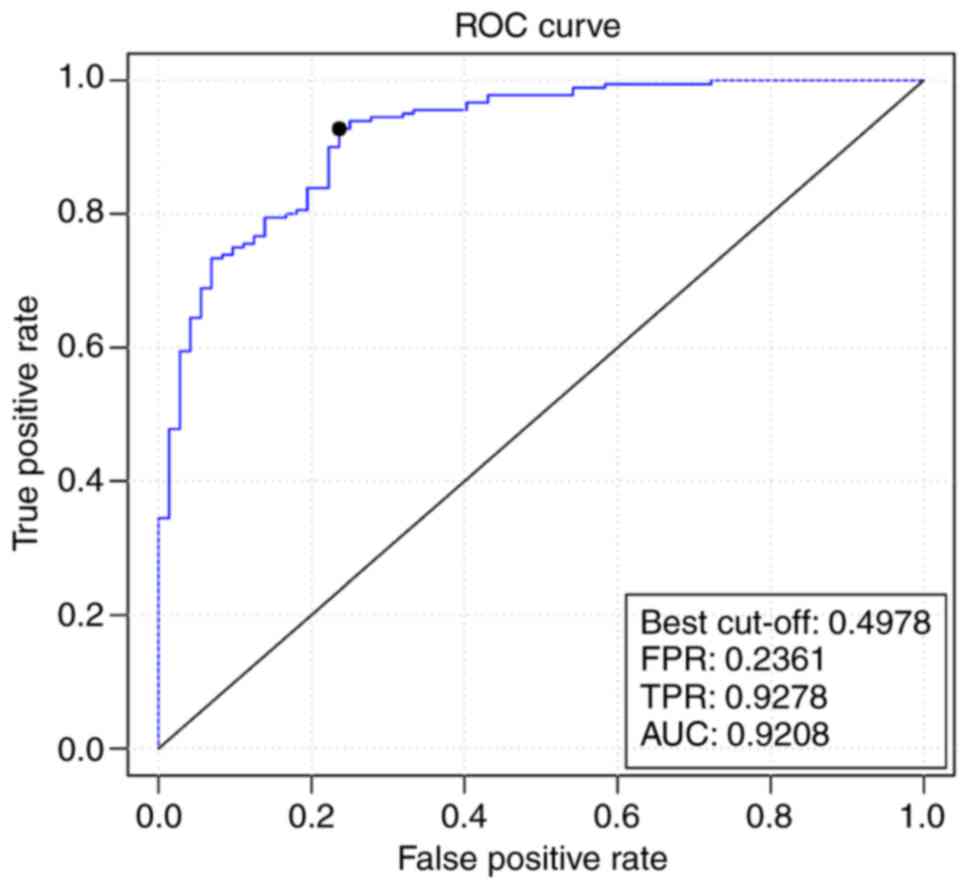
also verified using the independent microarray data GSE61144, and
the ROC curve is presented in Fig.
6. The predictive precision was 0.92, the average true positive
rate was 0.9278 and the average false positive rate was 0.2361.
Discussion
To identify the risk genes in myocardial infarction,
the GSE34198 microarray dataset was downloaded from the GEO
database, and 724 downregulated and 483 upregulated DEGs were
screened in patient samples compared with control samples. The PPI
network of myocardial infarction was comprised of 1,083 nodes
(genes) and 46,363 lines (connections). Using the neighborhood
scoring method, the top 100 feature genes in myocardial infarction
samples were identified as the disease feature genes, which allow
myocardial infarction samples to be distinguished from the control
samples. The RFE algorithm screened 15 risk genes, which were
utilized to construct a SVM classifier with an average precision of
88% to the patient samples following visualization by a confusion
matrix. The predictive precision of the classifier on another
microarray dataset, GSE61144, was 0.92, with average true positive
rate of 0.9278 and an average false positive rate of 0.2361. AKAP12
and GLRA2 were two of the risk genes identified.
AKAPs are scaffolding proteins that regulate the
cellular cyclic AMP response. Several AKAPs are reported to be
expressed in the heart, including AKAP18, AKAP79, AKAP6 and AKAP220
(28,29). AKAPs participate in cardiovascular
functions by various mechanisms. For example, AKAPs were reported
to anchor protein kinase A (PKA) in the sarcomere for the
phosphorylation of myofibril proteins in contractile responses
(30). In addition, AKAPs docked
APK in proximity of sarcomeric substrates to enhance cardiac
contractility (31). AKAPs mediate
certain phosphorylation events in the heart, and AKAP6 complex
disruption resulted in aberrant Ca2+ cycling, which was
associated with arrhythmia (32).
Loss of AKAP150 promoted pathological remodeling and heart failure
propensity by disrupting Ca2+ cycling and contractile
reserve (33). Furthermore, when
voltage-gated K+ currents were reduced in ventricular
myocytes following myocardial infarction, AKAP150 was reported to
be involved in the activation of calcineurin/nuclear factor of
activated T-cells (34). PKA is
involved in the progression of heart failure (35), therefore, AKAPs, which regulate the
activity of PKA, are also risk factors in heart failure. AKAP12 has
been associated with various cellular functions, including
cytoskeletal architecture and cell cycle regulation (36,37).
Activated AKAP12 has been observed in the plasma membrane, cell
periphery and perinuclear regions in the cytoplasm (38). Although no associations between
AKAP12 and heart disease have been previously reported, its
potential role can be inferred based on the functions of other
AKAPs.
Glycine is a simple physiological compound whose
function in cardiovascular disease is receiving increased attention
is research. Glycine was reported to protect against
ischemia-reperfusion injury in cells and isolated perfused organs
by inhibiting neuronal apoptosis in mice (39,40).
Glycine receptors have been identified in the myocardial cell
membrane, which aid the cytoprotective effects of glycine in
myocardial cells (41).
Furthermore, it was reported that the cytoprotective effect of
glycine against ATP depletion-induced injury may be mediated by the
glycine receptor in renal cells (42). GLRA2 is one type of glycine
receptor, and, currently, no direct evidence has revealed its role
in cardiovascular disease. However, the present study performed
bioinformatics analysis to demonstrated that GLRA2 was a risk gene
in myocardial infarction. Although the above result based on
bioinformatics analysis is important, confirmation of the
above-mentioned results is required by performing functional
studies, and the role of AKAP12 and GLRA2 genes in myocardial
infarction requires further investigation.
In conclusion, the results of the present study
indicate that AKAP12 and GLRA2 exert potential roles in the
development of myocardial infarction, potentially by influencing
cardiac contractility and protecting against ischemia-reperfusion
injury.
References
|
1
|
Coventry LL, Finn J and Bremner AP: Sex
differences in symptom presentation in acute myocardial infarction:
A systematic review and meta-analysis. Heart. 40:477–491. 2011.
|
|
2
|
Valensi P1, Lorgis L and Cottin Y:
Prevalence, incidence, predictive factors and prognosis of silent
myocardial infarction: A review of the literature. Arch Cardiovasc
Dis. 104:178–188. 2011. View Article : Google Scholar
|
|
3
|
Panza JA: Myocardial ischemia and the
pains of the heart. N Engl J Med. 346:1934–1935. 2002. View Article : Google Scholar
|
|
4
|
Langenbrunner JC, Marquez PV and Wang S:
Toward a Healthy and Harmonious Life in China: Stemming the Rising
Tide of Non-Communicable DiseasesHuman Development Unit; East Asia
and Pacific region. Washington, DC: The World Bank; 2011,
http://documents.worldbank.org/curated/en/618431468012000892/Toward-a-healthy-and-harmonious-life-in-China-stemming-the-rising-tide-of-non-communicable-diseasesOctober
21–2016
|
|
5
|
Velagaleti RS, Pencina MJ, Murabito JM,
Wang TJ, Parikh NI, D'Agostino RB, Levy D, Kannel WB and Vasan RS:
Long-term trends in the incidence of heart failure after myocardial
infarction. Circulation. 118:2057–2062. 2008. View Article : Google Scholar :
|
|
6
|
Pfeffer MA and Braunwald E: Ventricular
remodeling after myocardial infarction. Experimental observations
and clinical implications. Circulation. 81:1161–1172. 1990.
View Article : Google Scholar
|
|
7
|
Go AS, Mozaffarian D, Roger VL, Benjamin
EJ, Berry JD, Borden WB, Bravata DM, Dai S, Ford ES, Fox CS, et al:
Heart disease and stroke statistics-2013 update: A report from the
American Heart Association. Circulation. 127:e6–e245. 2013.
View Article : Google Scholar
|
|
8
|
Rosenberg L, Kaufman DW, Helmrich SP,
Miller DR, Stolley PD and Shapiro S: Myocardial infarction and
cigarette smoking in women younger than 50 years of age. JAMA.
253:2965–2969. 1985. View Article : Google Scholar
|
|
9
|
Leong DP, Smyth A, Teo KK, McKee M,
Rangarajan S, Pais P, Liu L, Anand SS and Yusuf S: INTERHEART
Investigators: Patterns of alcohol consumption and myocardial
infarction risk: Observations from 52 Countries in the interheart
case-control study. Circulation. 130:390–398. 2014. View Article : Google Scholar
|
|
10
|
Acute myocardial infarction and combined
oral contraceptives: Results of an international multicentre
case-control study: WHO Collaborative Study of Cardiovascular
Disease and Steroid Hormone Contraception. Lancet. 349:1202–1209.
1997. View Article : Google Scholar
|
|
11
|
Cassidy A, Mukamal KJ, Liu L, Franz M,
Eliassen AH and Rimm EB: High anthocyanin intake is associated with
a reduced risk of myocardial infarction in young and middle-aged
women. Circulation. 127:188–196. 2013. View Article : Google Scholar :
|
|
12
|
Freiberg MS, Chang CC, Kuller LH,
Skanderson M, Lowy E, Kraemer KL, Butt AA, Goetz Bidwell M, Leaf D,
Oursler KA, et al: HIV infection and the risk of acute myocardial
infarction. JAMA Intern Med. 173:614–622. 2013. View Article : Google Scholar :
|
|
13
|
Helgadottir A, Manolescu A, Thorleifsson
G, Gretarsdottir S, Jonsdottir H, Thorsteinsdottir U, Samani NJ,
Gudmundsson G, Grant SF, Thorgeirsson G, et al: The gene encoding
5-lipoxygenase activating protein confers risk of myocardial
infarction and stroke. Nat Genet. 36:233–239. 2004. View Article : Google Scholar
|
|
14
|
Do R, Stitziel NO, Won HH, Jørgensen AB,
Duga S, Merlini Angelica P, Kiezun A, Farrall M, Goel A, Zuk O, et
al: Multiple rare alleles at LDLR and APOA5 confer risk for
early-onset myocardial infarction. Nature. 518:102–106. 2015.
View Article : Google Scholar
|
|
15
|
Han H, Wang H, Yin Z, Jiang H, Fang M and
Han J: Association of genetic polymorphisms in ADH and ALDH2 with
risk of coronary artery disease and myocardial infarction: A
meta-analysis. Gene. 526:134–141. 2013. View Article : Google Scholar
|
|
16
|
Valenta Z, Mazura I, Kolár M, Grünfeldová
H, Feglarová P, Peleška J, Tomecková M, Kalina J, Slovák D and
Zvárová J: Determinants of excess genetic risk of acute myocardial
infarction-a matched case-control study. Eur J Biomed Inform.
8:34–43. 2012.
|
|
17
|
Gautier L, Cope L, Bolstad BM and Irizarry
RA: affy-analysis of Affymetrix GeneChip data at the probe level.
Bioinformatics. 20:307–315. 2004. View Article : Google Scholar
|
|
18
|
Liu Q, Wong L and Li J: Z-score biological
significance of binding hot spots of protein interfaces by using
crystal packing as the reference state. Biochim Biophys Acta.
1824:1457–1467. 2012. View Article : Google Scholar
|
|
19
|
Paic F, Igwe JC, Nori R, Kronenberg MS,
Franceschetti T, Harrington P, Kuo L, Shin DG, Rowe DW, Harris SE
and Kalajzic I: Identification of differentially expressed genes
between osteoblasts and osteocytes. Bone. 45:682–692. 2009.
View Article : Google Scholar :
|
|
20
|
Liu C and Xuan Z: Prioritization of
cancer-related genomic variants by SNP association network. Cancer
Inform. 14 Suppl 2:S57–S70. 2015.
|
|
21
|
Yu F, Yang Z, Hu X, Sun Y, Lin H and Wang
J: Protein complex detection in PPI networks based on data
integration and supervised learning method. BMC Bioinformatics. 16
Suppl 12:S32015. View Article : Google Scholar :
|
|
22
|
Liu AN, Wang LL, Li HP, Gong J and Liu XH:
Correlation between posttraumatic growth and posttraumatic stress
disorder symptoms based on pearson correlation coefficient: A
meta-analysis. J Nerv Ment Dis. 205:380–389. 2017. View Article : Google Scholar
|
|
23
|
Malta DC, Bernal RI, Almeida MC, Ishitani
LH, Girodo AM, Paixão LM, Oliveira MT, Junior Pimenta FG and Júnior
Silva JB: Inequities in intraurban areas in the distribution of
risk factors for non communicable diseases, Belo Horizonte, 2010.
Rev Bras Epidemiol. 17:629–641. 2014.(In English, Portuguese).
View Article : Google Scholar
|
|
24
|
Metsalu T and Vilo J: ClustVis: A web tool
for visualizing clustering of multivariate data using principal
component analysis and heatmap. Nucleic Acids Res. 43:W566–W570.
2015. View Article : Google Scholar :
|
|
25
|
Qureshi MN, Min B, Jo HJ and Lee B:
Multiclass classification for the differential diagnosis on the
ADHD subtypes using recursive feature elimination and hierarchical
extreme learning machine: Structural MRI study. PLoS One.
11:e01606972016. View Article : Google Scholar :
|
|
26
|
Matwin S and Sazonova V: Direct comparison
between support vector machine and multinomial naive Bayes
algorithms for medical abstract classification. J Am Med Inform
Assoc. 19:9172012. View Article : Google Scholar :
|
|
27
|
Park HJ, Noh JH, Eun JW, Koh YS, Seo SM,
Park WS, Lee JY, Chang K, Seung KB, Kim PJ and Nam SW: Assessment
and diagnostic relevance of novel serum biomarkers for early
decision of ST-elevation myocardial infarction. Oncotarget.
6:12970–12983. 2015. View Article : Google Scholar :
|
|
28
|
Kapiloff MS, Schillace RV, Westphal AM and
Scott JD: mAKAP: An A-kinase anchoring protein targeted to the
nuclear membrane of differentiated myocytes. J Cell Sci.
112:2725–2736. 1999.
|
|
29
|
Redden JM and Dodge-Kafka KL: AKAP
phosphatase complexes in the heart. J Cardiovasc Pharmacol.
58:354–362. 2011. View Article : Google Scholar :
|
|
30
|
Perino A, Ghigo A, Scott JD and Hirsch E:
Anchoring proteins as regulators of signaling pathways. Circ Res.
111:482–492. 2012. View Article : Google Scholar :
|
|
31
|
Sumandea CA, Garcia-Cazarin ML, Bozio CH,
Sievert GA, Balke CW and Sumandea MP: Cardiac troponin T, a
sarcomeric AKAP, tethers protein kinase A at the myofilaments. J
Biol Chem. 286:530–541. 2011. View Article : Google Scholar
|
|
32
|
Lehnart SE, Wehrens XH, Reiken S, Warrier
S, Belevych AE, Harvey RD, Richter W, Jin SL, Conti M and Marks AR:
Phosphodiesterase 4D deficiency in the ryanodine-receptor complex
promotes heart failure and arrhythmias. Cell. 123:25–35. 2005.
View Article : Google Scholar :
|
|
33
|
Li L, Li J, Drum BM, Chen Y, Yin H, Guo X,
Luckey SW, Gilbert ML, McKnight GS, Scott JD, et al: Loss of
AKAP150 promotes pathological remodelling and heart failure
propensity by disrupting calcium cycling and contractile reserve.
Cardiovasc Res. 113:147–159. 2017. View Article : Google Scholar
|
|
34
|
Nieves-Cintrón M, Hirenallur-Shanthappa D,
Nygren PJ, Hinke SA, Dell'Acqua ML, Langeberg LK, Navedo M, Santana
LF and Scott JD: AKAP150 participates in calcineurin/NFAT
activation during the down-regulation of voltage-gated K(+)
currents in ventricular myocytes following myocardial infarction.
Cell Signal. 28:733–740. 2016. View Article : Google Scholar
|
|
35
|
Bockus LB and Humphries KM: cAMP-dependent
protein kinase (PKA) signaling is impaired in the diabetic heart. J
Biol Chem. 290:29250–29258. 2015. View Article : Google Scholar :
|
|
36
|
Nelson PJ, Moissoglu K, Vargas J Jr,
Klotman PE and Gelman IH: Involvement of the protein kinase C
substrate, SSeCKS, in the actin-based stellate morphology of
mesangial cells. J Cell Sci. 112:361–370. 1999.
|
|
37
|
Hehnly H, Canton D, Bucko P, Langeberg LK,
Ogier L, Gelman I, Santana LF, Wordeman L and Scott JD: A mitotic
kinase scaffold depleted in testicular seminomas impacts spindle
orientation in germ line stem cells. Elife. 4:e093842015.
View Article : Google Scholar :
|
|
38
|
Yan X, Walkiewicz M, Carlson J, Leiphon L
and Grove B: Gravin dynamics regulates the subcellular distribution
of PKA. Exp Cell Res. 315:1247–1259. 2009. View Article : Google Scholar :
|
|
39
|
Petrat F, Boengler K, Schulz R and de
Groot H: Glycine, a simple physiological compound protecting by yet
puzzling mechanism(s) against ischaemia-reperfusion injury: Current
knowledge. Br J Pharmacol. 165:2059–2072. 2012. View Article : Google Scholar :
|
|
40
|
Lu Y, Zhang J, Ma B, Li K, Li X, Bai H,
Yang Q, Zhu X, Ben J and Chen Q: Glycine attenuates cerebral
ischemia/reperfusion injury by inhibiting neuronal apoptosis in
mice. Neurochem Int. 61:649–658. 2012. View Article : Google Scholar
|
|
41
|
Qi RB, Zhang JY, Lu DX, Wang HD, Wang HH
and Li CJ: Glycine receptors contribute to cytoprotection of
glycine in myocardial cells. Chin Med J (Engl). 120:915–921.
2007.
|
|
42
|
Pan C, Bai X, Fan L, Ji Y, Li X and Chen
Q: Cytoprotection by glycine against ATP-depletion-induced injury
is mediated by glycine receptor in renal cells. Biochem J.
390:447–453. 2005. View Article : Google Scholar :
|